

Before diving directly into technical definition, let's take few scenarios.
Scenario 1
If I share two documents or two text files - which has few sentences in it. How will you identify whether both documents related with same topic or different topic ? OR How much they similar? Are both are same? Are they 70% same ? or Are they totally different?
Yes - You can go though both documents and read it's content and then decide whether they are similar or not or till what %age they are similar. But Is this feasible for large documents ? Is this feasible if I gave one input documents and ask to find similar documents from thousands of documents.?
Ofcourse Answer is NO
Scenario 2
You upload one image on google in Google Image Search Bar - and Google search similar images from it's database. How that's work?
All above scenarios we can achieve with 'Cosine Similarity'.
Let's consider very simple example -
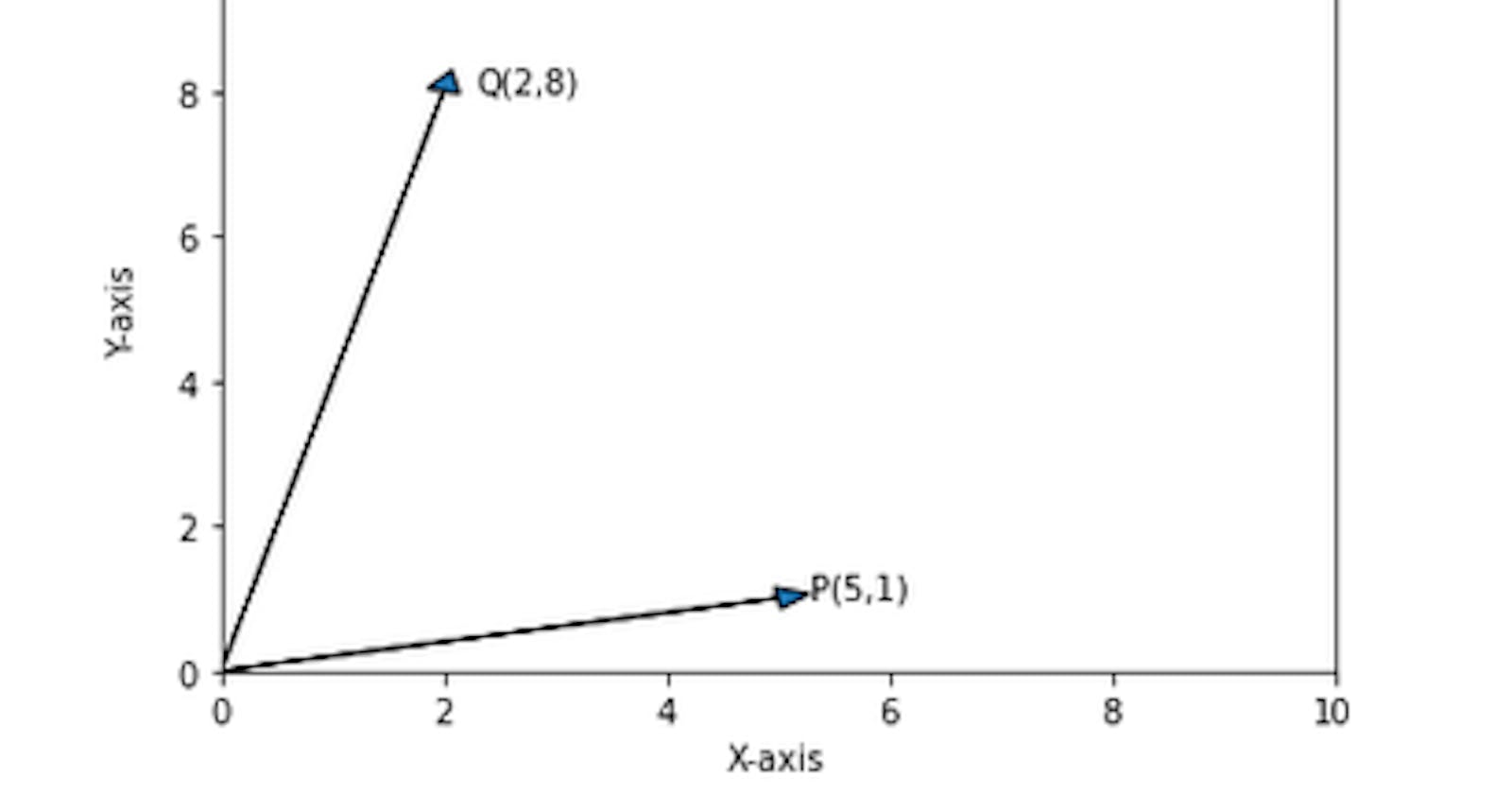
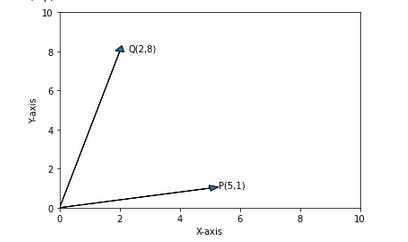
Let's take two array(vector) P & Q
P = np.array([5,1])
Q = np.array([2,8])
Let's draw it via matplotlib
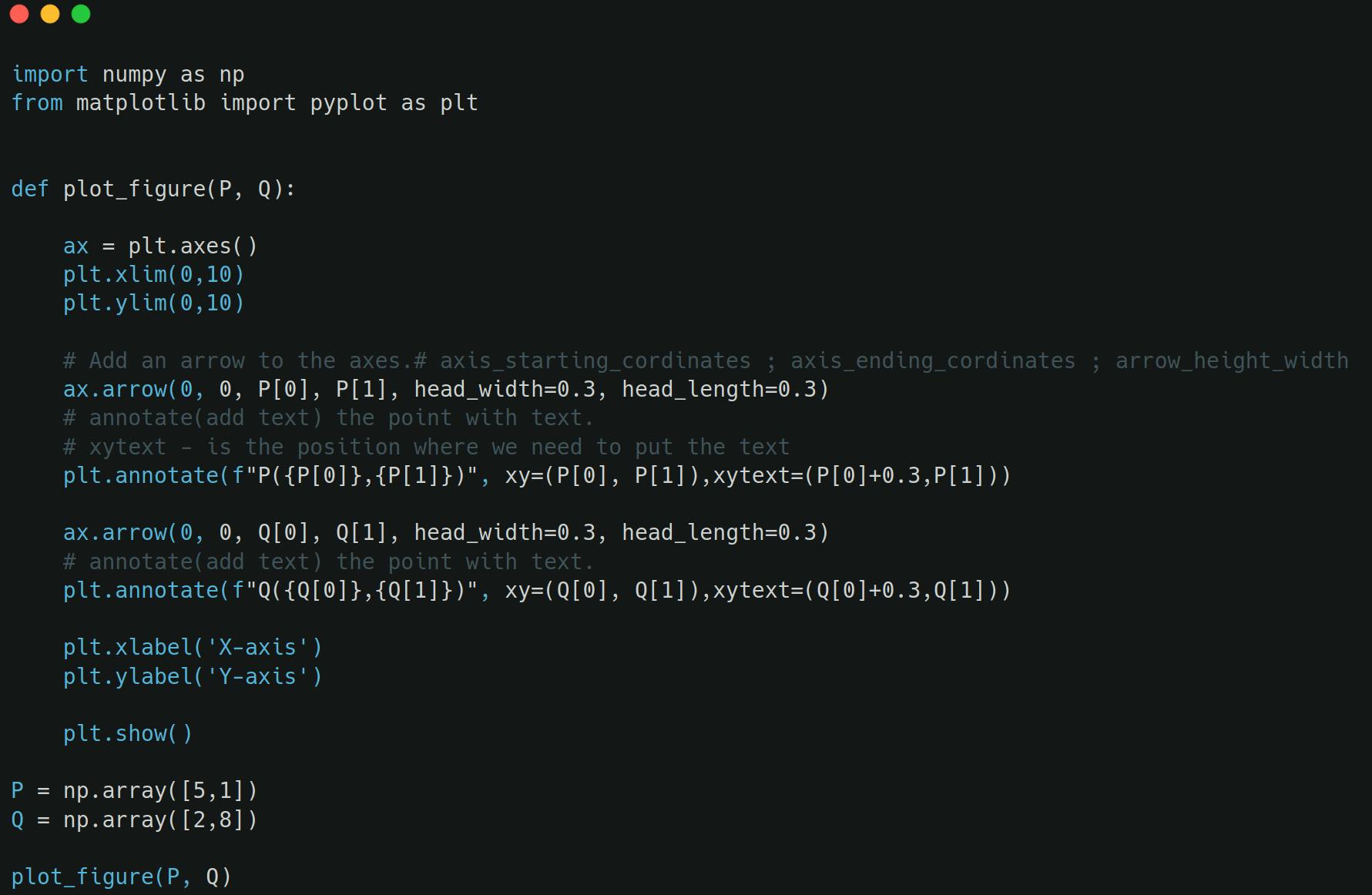
Code to draw above is below -
We could see in above diagram - there is some angle between two axis. and the cosine value of that angle determines 'Cosine Similarity'
Formula of cosine Similarity is :
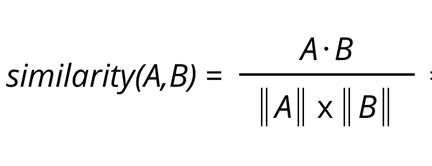
So, we have two vectors P = [5,1] & Q = [2,8]
Let's find Numerator (P.Q) ==> 52 + 18 ==> 10 + 8 ==> 18
Let's find Denominator i.e. |P| & |Q| individually
|P| = sqrt ( 5^2 + 1^2) => sqrt(25+1) => sqrt(26)
|Q| = sqrt ( 2^2 + 8^2) => sqrt (4 + 64) => sqrt (68)
Cosine Similarity = 18 / ( sqrt(26) * sqrt(68) ) ==> 0.428
if both points are same, then angle between axis is 0 - and Cosine Similarity will be 1 i.e. both vectors are similar.
So if angle between axis is less , it has more cosine similarity and if angle between axis is more, then it has less cosine similarity.
Python Code for finding the cosine Similarity
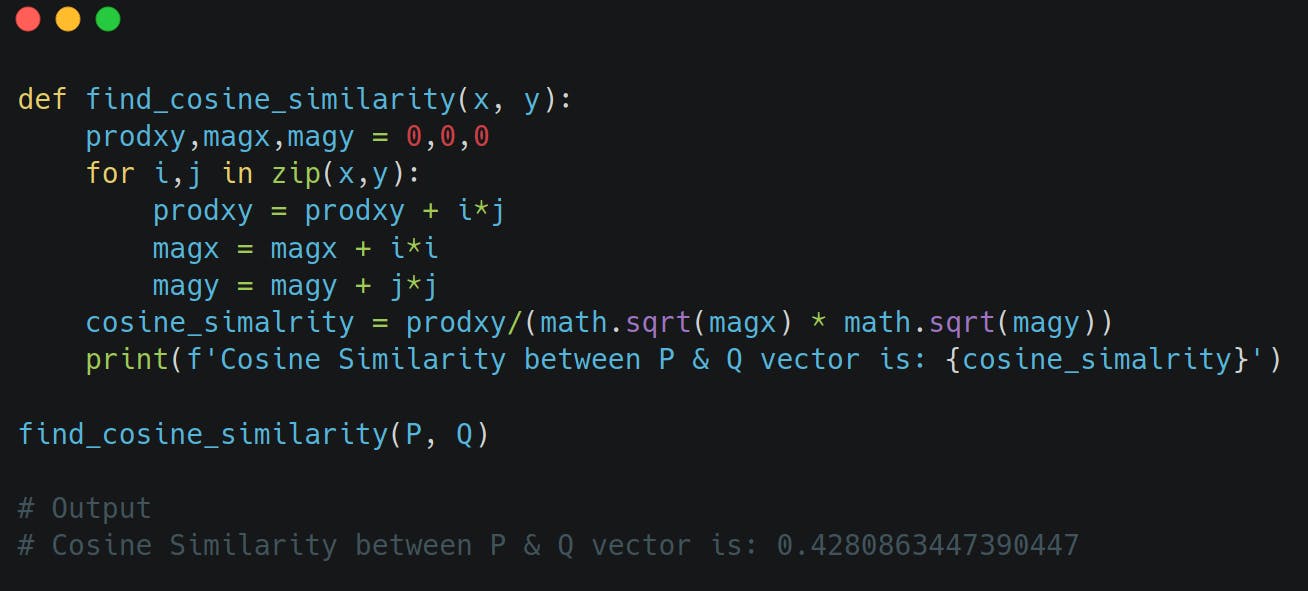
Example 1
Document Similarity
Let's say we have 2 documents which has below content. For the simplicity we take very simple example.
doc_1 = "My First Name is Sumanshu"
doc_2 = "My Last Name is Nankana"
To find the similarity between 2 documents. We need to find the Cosine Similarity. And to find Cosine Similarity, we need the vector of array.
So, first we need to convert both documents into a vector/array
To find the vectors, we need all words and find how many times that word is present in that document.
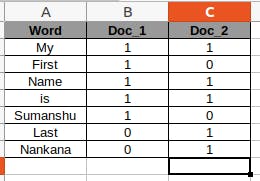
P = [1,1,1,1,1,0,0] Q = [1,0,1,1,0,1,1]
Let's call above function on these vectors.
find_cosine_similarity(P, Q)
Cosine Similarity between P & Q vector is: 0.5999999999999999
Example 2
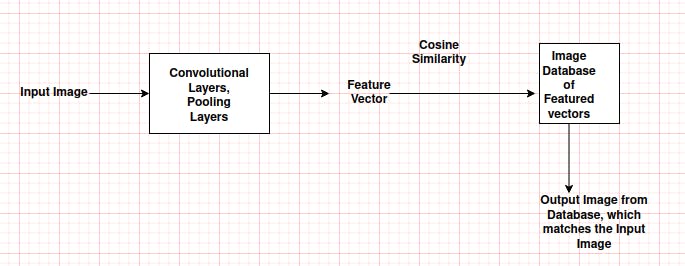
Similarly we can perform the 'Reverse Image Search' i.e. give one input as a Image and find similar images form database.
So to find Cosine Similarity, we need vectors.
So first we need to convert Input Image into a Vector. Also we can convert database images into a list of vectors.
We can get vectors by passing Image from a CNN (Convolutional Neural Network Layers) - which covert image into a vector (which is actually a features).
Cosine Similarity can be used in Recommendation System like Movie Recommendation, Product Recommendation.
Cosine Similarity is not the only method in market, there are so many other methods available to available to achieve all these scenarios.